
Putting Teeth in Our Public Cloud
Published July 2nd, 2014
Less than a year ago ago my team started building Rackspace OnMetal — the project was a whirlwind. Below I have outlined some of our major decisions as the product progressed and my own experiences. I am very thankful to the many different Rackers that took part in this project.
Why would you build OnMetal?
There was no master plan from 5 years ago to build OnMetal. A handful of advocates within Rackspace pushed to create the OnMetal product, because of our joint experiences in building and using infrastructure.
When Rackspace acquired Cloudkick 3.5 years ago we were running hundreds of cloud instances — we were spending huge amounts of engineering effort working around their flaws and unpredictability. The technical challenge was fun. We got to know the internals of Apache Cassandra really well. We would spend weeks rewriting systems, an eternity in startup-time, just because a cloud server with 8 gigabytes of RAM was falling over.
Once acquired, we escaped virtualization and entered the supposed nirvana of designing custom servers. We customized servers with an extra 32 gigabytes of RAM or a different hard disk model. Because of our different generations of data centers, we had to vary cabinet density based on power and cooling. We also had to build capacity models for our network switches and pick different models, but why was I doing this? I just want to build products. I do not to want worry about when we should be buying a larger piece of network equipment. I also definitely do not care how many kilowatts per cabinet I can put into one data-center but not the other.
Starting a team
By the summer of 2013 I was looking for a new project. I had spent the last 12 months as part of the Corporate Development team working mostly on partnerships and acquisitions. My role involved bringing technical expertise to bear on external products and judging how they could match our internal priorities. It was a fun experience and I enjoyed meeting startup founders and learning more about business, but I wanted to make products again.
Ev, one of the Mailgun founders, had recently moved to San Antonio and was also looking for a new project. Ev and I both wanted to build an exciting and impactful product. We had both experienced building infrastructure products on top of virtualized clouds and colocation. We saw opportunities for improvement of multi-tenancy in a public cloud, and at the same time we could attack the complexities found with colocation. After a couple brainstorming sessions, we agreed about the basics of the idea: Deliver workload optimized servers without a hypervisor via an API. We called this project “Teeth”. Teeth is an aggressive word; we wanted our cloud to project a more aggressive point of view to the world. We also knew that the code name of Teeth was so ridiculous that no one from marketing would let us use it as the final name.
Teeth is Born!
![]()
The Teeth team logo. @fredland sketched it on our team whiteboard, we adopted it.
The Teeth project started as part of our Corporate Strategy group — a miniature startup — outside of our regular product development organization. This removed most of the organizational reporting and structure, and gave our day to day a more startup-like feeling. This let us get prototypes going very quickly, but definitely had trade-offs in other areas. We found that while we were building a control plane for servers, integration with other teams like Supply Chain or Datacenter operations was critical — but because we were not in the normal product organization we had to use new processes to work with these teams.
As we kicked off Teeth, it was just a team of two: Ev and myself. We had gotten signoff at the highest levels, but we were still just two people in a 5,500 person company. Getting hardware in a datacenter is easy at Rackspace, but it was clear for our first hardware the project needed a more lab-like environment. I wanted to be able to crash a server’s baseboard management card (BMC) and not have to file a ticket for someone physically power cycle the server. I was working out of the Rackspace San Francisco office, and unlike our headquarters we didn’t have a real hardware lab with extra hardware lying around.
We put in a request for hardware through our standard channels. We were told a timeline measured in weeks. We waited a few weeks, but the priority of our order was put behind other projects. This was a legitimate reaction from internal groups, they had much larger projects on tighter timelines, more important than two engineers wanting to fool around in a lab. After conferring with Ev, we did what any reasonable startup would do: I went on to Newegg.com and bought 3 servers to be our first test kit. My only requirement for the servers is that they had working BMCs with IPMI, so I ordered 3 of the cheapest SuperMicro servers on Newegg. They arrived in the office 48 hours later.
Using Open Compute
Rackspace knew it does not create value from proprietary server designs, we create value from reducing the complexity of computing for our customers. However, before Teeth, we had tinkered, but hadn’t yet deployed a large scale system using OCP servers.
Rackspace has supported the Open Compute Project (OCP) from the beginning of the project. Our team is mostly software-people, and we love open source. We knew it was risky and could take longer to build Teeth on top of OCP, but we believed fundamentally that OCP is how servers should be built.
Once we picked the OCP platform, we received OCP servers into our lab environment and we iterated on the BIOS and Firmwares with our vendors. We required specific security enhancements and changes to how the BMC behaved for Teeth.
Using OCP has been a great experience. We were able to achieve a high density, acquire specific hardware configurations, customize firmwares and still have a low cost per server. As the OnMetal product continues to mature, I want our team to push back our learnings to the OCP community, especially around the BIOS, Firmware, and BMCs.
The move to OpenStack
OpenStack Nova has had a baremetal driver since the Grizzly release, but the project has always documented the driver as experimental. It remained experimental because it had only a few developers and many bugs. The Nova community also realized that a baremetal driver had a scope much larger than all of its other drivers. It had to manage physical hardware, BMCs, top of rack switches, and use many low level protocols to do this. This realization by the community led to OpenStack Ironic being created as a standalone baremetal management project. The goal is to have a small driver in Nova, and the majority of the complexities can be handled in Ironic.
Researching OpenStack Ironic
When the team started building our Teeth prototype, OpenStack Ironic did not seem finished and we weren’t sure how quickly it would progress. Researching the project we found that the default PXE deployment driver was the main focus of development.
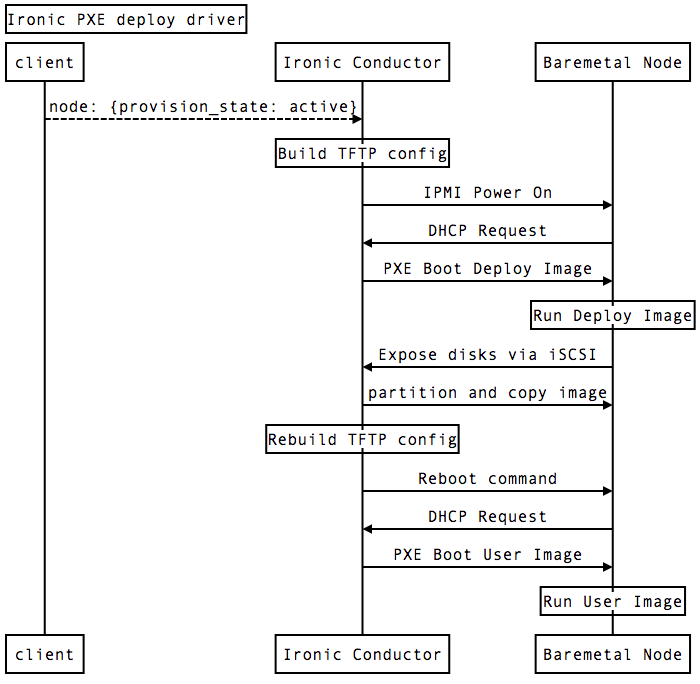
The Ironic PXE deployment method works by running a TFTP server on each Ironic Conductor, and as the node boots serving out a custom configuration for each baremetal node. Once the baremetal node is booted into the Deployment image, the deployment image exports local disks via iSCSI back to the Ironic Conductor. The Ironic Conductor can then write out the requested image using dd. Once this is complete the TFTP configuration is rewritten to reference the User image, and then the Baremetal node is rebooted.
As we researched the existing Ironic PXE deployment method we were unhappy for these reasons:
- Minimum of two power cycles to provision a node, increasing the time to provision a baremetal node significantly.
- The Deployment Image had limited functionality, and we had difficulty extending the Ramdisk mode of diskimage-builder. We wanted to accomplish tasks like flashing firmwares and using SATA secure erase.
- The Ironic Conductors rewrite the TFTP configurations multiple times for different baremetal node states, increasing complexity and introducing systems that are harder to make highly available.
- The Ironic Conductors being responsible for writing disk images over iSCSI presented a performance bottleneck.
Because of these reasons we started the Teeth prototype outside of OpenStack Ironic. We still wanted Nova integration, so we built our prototype as a Nova driver, and separate control plane, conceptually similar to Ironic’s architecture.
Back into OpenStack
By early 2014 we saw that the control plane we were building mirrored Ironic closely. We were solving the same problem, and we wanted our users to use the same Nova public API. Looking at what we had built and looking at Ironic again, we saw we only needed to change how Ironic deployments themselves worked. We decided to attend the Ironic mid-cycle meetup in February 2014. At the meetup our team explained how our Teeth prototype used an “Agent” based model, where a long-running Agent running in a RAM disk can take commands from the control plane. This Agent based approach eventually was renamed Ironic Python Agent (IPA, yes, the team was excited to name their software after beer).
The Ironic Python Agent presents an HTTP API that the Ironic Conductor can interact with. For IPA, we decided early to build upon two architectural pillars:
- Use HTTP for as much as possible, bootstrapping out of old and low level protocols.
- Do as much work before an instance is actually deployed, amortizing the costs of rebooting or flashing firmware to happen before a tenant ever asks for a baremetal node.
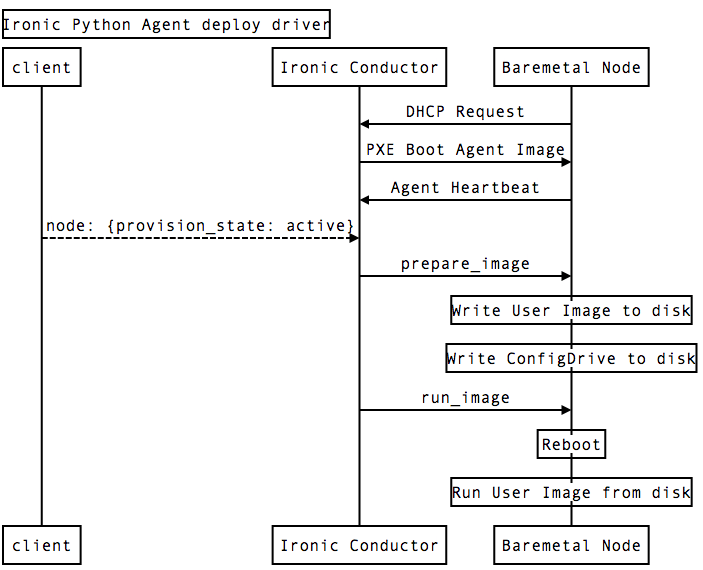
With IPA the DHCP, PXE and TFTP configurations become the static for all baremetal nodes, reducing complexity. Once running, the Agent sends a heartbeat to the Ironic Conductors with hardware information. Then the Conductors can order the Agent to take different actions. For example in the case of provisioning an instance, the Conductor sends an HTTP POST to prepare_image with the URL for an Image, and the Agent downloads and writes it to disk itself, keeping the Ironic Conductor out of the data plane for an image download. Once the image is written to disk, the Ironic Conductor simply reboots the baremetal node, and it boots from disk, removing a runtime dependency on a DHCP or TFTP server.
After the successful mid-cycle meetup and the welcoming attitude we saw, we decided to become an active participant with the community. We abandoned our proprietary prototype, and have been contributing to the Ironic Python Agent deployment method and the Ironic control plane inside the OpenStack community.
Integrating back into Rackspace
As our small team progressed in developing Teeth, we began to see a need to integrate into existing Rackspace products and organizational processes. For example we wanted the OnMetal flavors to show up in the standard Nova API, along all of our other flavors. To implement this we needed our Ironic system to be integrated with Nova. We did this by creating a new Nova cell just for the OnMetal flavor types. The top level cell only needs basic information about our instances, and then the nova-compute instances in our cell load the Ironic virt driver where all the hard work happens.
As we integrated software systems, our startup behaviors and structures were less valuable. We needed to reduce confusion and tension with the rest of the company. Once we moved to an integration mode, we moved the engineering team back into our normal product development organization. The teams quickly started working together closely and we hit our execution targets. In some ways it was like a mini-startup being acquired and quickly integrating into a larger company.
Announcing OnMetal
We wanted to announce Teeth to the public this summer. We considered the OpenStack Summit in Atlanta — we believe the combination of OpenStack software with Open Compute hardware is a great message for the community. But instead of announcing a product, we preferred to focus our discussion with the community at the OpenStack Summit on the Rebel Alliance vision.
The Structure Conference presented a great opportunity to show our message. Our message is that platforms should be open. That offerings should be specialized for their workloads. That using Containers and OnMetal are another way we can reduce complexity from running large applications. That we are not stuck on a virtualization only path. That our customers find value from reducing complexity and having a best fit infrastructure.
After working on the Teeth project it felt great to see our message has been well received by both the press and Twitter commentary. Interest in the OnMetal product offering has been overwhelming, and now our team is focusing on fixing as many bugs as possible, onlining more cabinets of OCP servers for capacity, and preparing for the general availability phase of the product.
Thanks to Alexander Haislip, Robert Chiniquy and Chris Behrens for reviewing drafts of this post.
Written by Paul Querna, CTO @ ScaleFT. @pquerna