
Transforming Streams
Published October 6th, 2010
_Preface: Streams are complicated. I’ve tried to simplify and skip whole topics were possible, but this is still a long post. _
About Streams
Lets talk about Streams. A Stream is the abstraction that we use to represent a flow of data, going from the source, being transformed, and going to a destination.
Speaking generically, modern web servers don’t serve static, pre-computed files. Apache could do that fine, and if you really need static performance, CDNs are very good at static files, and relatively cheap. To me, the interesting servers, HTTP and otherwise, are ones that combine data from many sources and apply many transformations like templates, compression, or encryption. Most pages you view today are also completely customized, with silly things like saying Hello $name, to complete customization of what content you see. Dynamic content is only growing in scope, and that is why understanding streams and how to transform them is so important.
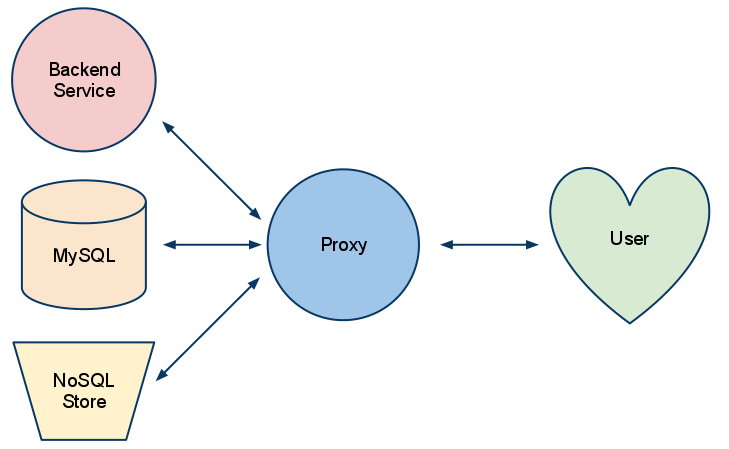
The higher level abstraction of taking various client inputs, requesting data, and transforming it, is commonly called a Proxy. Proxies take streams on both ends, apply a transformation, and send it to a client. This is where Node.js comes in — It is one of the best architectures for proxying and transformations. Ryan Dahl, the creator of Node.js, has talked about Node.js as just a proxy server; In this interview with DailyJS, Ryan explains his belief about proxying and transformation of data:
I think most of the programs, or a large part of the programs that we write, are just proxies of some form or another. We proxy data from a database to a web browser, but maybe run it through a template first and put some HTML around or do some sort of logic with it. But largely, we’re just passing data from one place to the other.
This idea though, of servers managing streams from various sources, its not a new one at all. It all ties back to the Unix command line, with the pipes between programs. So, lets take a little trip down history lane, how streams, how transformations, and the surrounding infrastructure has evolved over the last 15 years.
A brief History of Streams in the HTTP Space
Apache 1.x
Apache, including the now EOLed 1.3.x branch is a titan of open source software. It has maintained significant market share still today, years after any features have been added, and 9 years after Apache 2.0 was released.
The problem was, Apache 1.3.x (and all earlier versions for that matter), didn’t handle streams very well. Simple transformations like compression of response bodies in HTTP, also known as gzip or deflate encoding, were very complicated issues in Apache 1.3. These limitations also made it difficult to support important optimizations like Sendfile in non-core modules. This inability to handle streams is one of the core reasons Apache 2.0 was built.
An example is the commonly used mod_gzip module, only worked on purely static files. If your content was generated by PHP, or modperl, you couldn’t use modgzip. This led to PHP adding things like ob_gzhandler, which let your PHP application do gzip or deflate encoding itself. This was because there was no way to intercept the stream of data. mod_gzip’s only option was to take over as the source of the data, replacing the core static file handler.
Another example of the pain that this inability to deal with streams, were the mod_ssl and Apache-SSL projects. In part because of the terrible restrictions on cryptography at the time, both projects provided a set of patches against Apache 1.3, in order to even operate. But fundamentally, they needed to patch Apache in order to intercept data before it was written to a socket. Luckily, they both worked with more than static files, but they were severely limited in their flexibility, and because of their position in the stack, taking over the write calls right before the TCP socket, it was difficult to optimize the situation.
The lesson was learnt in Apache, we needed streams of data, with a way to transform them. This led to the design and development of Apache 2.
Apache 2: Buckets, Brigades and Filters
Apache 2 added many features, but one of the main drivers was the adoption of streams, along with their transformations as a core concept. In Apache 2, Buckets were the basic data type of the streams. A Bucket could represent a block of memory, a file on disk, a socket, metadata, or a dozen other possible sources of data. The Bucket API provided a clean way to abstract providing access to these various data sources in a consistent, and mostly performant way.
A group of buckets, is called a Brigade. A Bucket Brigade contains list of buckets, which can then be processed in various ways. For example, a client socket would generated a bucket brigade as input, and it would consume a brigade created by a content handler like PHP. These brigades allowed easy transformations, since you could change a bucket, and replace its positon in the brigade with different data. This lead to mod_deflate and mod_ssl becoming standard modules. Apache Tutor has a great article on Apache 2’s bucket brigades if you want a more in-depth, code level explanation.
Making the construction of output filters an easy task lead to explosion of various transformation modules. I wrote many modules that exploited this ability, for example: highlighting source code, another SSL implemation in mod_gnutls, and streaming inline XSLT transformations. With Bucket brigades and output filters, it was very easy to write an efficient stream processor, and modules authors all took advantage of this.

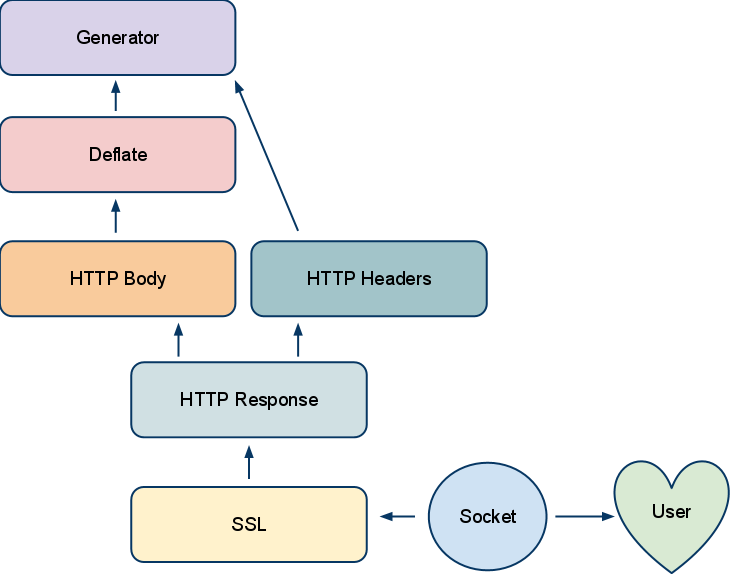
In the picture above, PHP is your content generator. It pushes a bucket brigade to deflate, which processes it and then hands it to the SSL filter. Once the SSL filter has encrypted the data, it is handed off to the Core Output Filter, which handles many optimizations like doing sendfile if possible or a writev with TCP_CORK, and asynchronous write completion. Overall I believe the output filter architecture was a success. It allowed innovation to happen in modules, and to not be stagnated with patching the core. Apache’s success has always been about the core providing a framework to build upon, and the output filter APIs struck a good balance between complexity and simplicity for people writing custom modules.
While these improvements are genuine, there were still several core problems, some of which were implementation decisions in Apache 2, and others were problems with the design:
- Flow control: Because of how output filters call the next filter in the chain, inside their own callstack, it is difficult for Apache itself to control the stack. This issue prevents many optimizations or changes in design, because with the API, your generator or filter is in control of calling the next item in the chain. This also means every filter needs to handle special cases, like errors or metadata buckets in a graceful manner.
- Async: I didn’t cover input filters in depth here, but essentially they are allowed to block indefinitely, and there is not a viable way to fix them. This means blocking IO will be nearly impossible to ever eliminate in an Apache 2.x based architecture. The Event MPM that I helped write tries to dance around this with a few well placed hacks, but it has to fallback to blocking behaviors once modules like mod_ssl are involved.
Serf to the rescue
Greg Stein and Justin Erenkrantz started seeing these issues in the bucket brigade design, and began a refactoring in the form of the Serf library, which is an HTTP client library. Serf’s goals included being a completely asynchronous HTTP client library, which under the traditional bucket brigades model was very difficult to accomplish.
Instead of using a linked list of Buckets like the Apache 2 brigade model, Serf’s buckets form a hierarchy. The control of flow is also completely different; Instead of being passed a brigade to process, you ask a bucket if it has any data available by making a read() call on it. That bucket in turn calls its parents, asking them if they have data, until you get all the way back to your content generator bucket. Any bucket can return EAGAIN, meaning it doesn’t have data right now, but it will in the future. This is a pull model for the streams.
In this example, when a socket is writable, it calls the SSL bucket, asking it to fill a buffer. The SSL bucket calls to its parents, which call their parents, until a buffer has data, and if they give it data, the SSL bucket transforms the data, and returns this now encrypted buffer to the socket. Then the Serf event loop can write to the socket at its leisure, enabling asynchronous behavoir.
This means writing to your socket can be done inside an event loop. The callstack when you are writing to a socket is at the top level, since you just get a buffer from a bucket, and are free to write it to the socket however you wish. This is contrasted with the Apache 2 filters model, where your entire set of filters will be in the callstack when you are writing to the socket.
Serf’s design has so far been successful in building the client library, though a full server has not yet been implemented using this hierarchal bucket design. This means some of the details of optimizations like sendfile haven’t ever been figured out completely, but the basic plan is in place. Serf has also some difficulties in the past with two way transformative streams, SSL being a good example — not so much the SSL part, but memory lifetime issues partly caused by how it was using pools. These issues have largely been resolved at this point
Node.js’ approach to streams
Node.js is different. It’s streams are built around two main concepts. The first is the Stream interface, which is a series of APIs and Event types to represent either a read or a write stream. The second is the sys.pump interface, for chaining transformative streams together.
In practice, you end with something like this:

An interesting part of the Node.js design is that sys.pump is used in-between most streams, you can build in better flow control and call stack control than in the Apache 2 or even Serf designs. It avoids a long call stack to push data, instead each sys.pump instance is responsible for listening to events on their individual Read Stream, and writing that data, if possible to the output stream.
The design used by Node, with the combination of APIs and Events leads to Streams being an elegant and simple interface. This is a good thing, because Node is all about exposing a powerful mechanism for developing servers in an easy to use wrapper.
The Node design is a good one, but it has a series of problems:
- Memory buffers only: A major limitation of the current Node.js design is that under the stream API, each chunk of data must be a single Buffer or a String — a single memory buffer. This means that data coming from another source, such as a static file, must be read into memory first.
- Sendfile optimizations: Since it is a memory buffer, this currently stops automatic optimizations like sendfile. Unlike Apache 2’s or Serf’s architecture, which let core code automatically decide to use sendfile if the data to be written to a socket is of the correct source type, you must manually setup the sendfile call, outside of the stream structure.
- Buffers are too nice: The Buffer API is too nice to the user, which makes it very hard to have a different backend implementation, like a read only FileBuffer.
- SSL is currently broken: It has been noted in other places, but SSL support in Node is currently lackluster. The secure stream implementation likes to hang and not pass your data along. I am hacking on a new approach in the Selene Project, but realistically its a slow project.
- Socket write() is a lie: In the diagram above, I also massively simplified how writing to a TCP socket works in Node; It is a lie, just like the cake. Currently when you write to a socket, it automatically buffers in memory if the socket would block. While this behavior can be undesired, it does lend itself to some creative optimizations in the long run. If at the end of an event cycle Node sees more than one buffer pending on a single socket, it could write all of them together in a single writev() call.
Having said all of this, the problems in Node.js all relatively small compared to where Apache 1.3.x was. All things that can be solved. My biggest concern is figuring out how to represent file chunks inside Node Streams — once that is figured out, the rest of these issues can all be knocked out one by one, most likely without any API changes.
Thanks to Geoff and mjr_ for reading drafts of this and providing feedback.
Written by Paul Querna, CTO @ ScaleFT. @pquerna